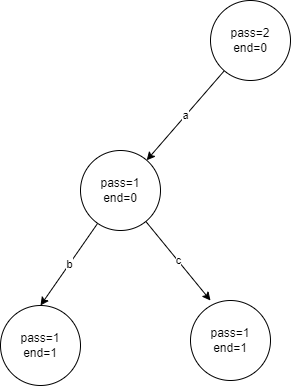
classTrie { public: int nexts[MAX][26] = { {0} }; int pass[MAX] = { 0 }; int end[MAX] = { 0 }; int cnt = 1; Trie() { cnt = 1; } // 插入word voidinsert(string word){ int cur = 1; pass[cur]++; for (auto c : word) { // 如果c不存在路径中 则新建一条路径 int path = c - 'a'; if (nexts[cur][path] == 0) { nexts[cur][path] = ++cnt; } cur = nexts[cur][path]; pass[cur]++; } end[cur]++; } // 查询word个数 intcountWord(string word){ int cur = 1; for (auto c : word) { int path = c - 'a'; if (nexts[cur][path] == 0) return0; cur = nexts[cur][path]; } return end[cur]; } // 查询前缀 intcountPrefix(string word){ int cur = 1; for (auto c : word) { int path = c - 'a'; if (nexts[cur][path] == 0) return0; cur = nexts[cur][path]; } return pass[cur]; } // 删除word voiderase(string word){ if (countWord(word) > 0) { int cur = 1; pass[cur]--; for (auto c : word) { int path = c - 'a'; if (--pass[nexts[cur][path]] == 0) { nexts[cur][path] = 0; return; } cur = nexts[cur][path]; } end[cur]--; } }