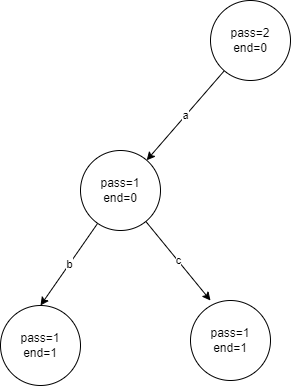
classTrie { public: int nexts[MAX][26] = { {0} }; int pass[MAX] = { 0 }; int end[MAX] = { 0 }; int cnt = 1; Trie() { cnt = 1; } // 插入word voidinsert(string word){ int cur = 1; pass[cur]++; for (auto c : word) { // 如果c不存在路径中 则新建一条路径 int path = c - 'a'; if (nexts[cur][path] == 0) { nexts[cur][path] = ++cnt; } cur = nexts[cur][path]; pass[cur]++; } end[cur]++; } // 查询word个数 intcountWord(string word){ int cur = 1; for (auto c : word) { int path = c - 'a'; if (nexts[cur][path] == 0) return0; cur = nexts[cur][path]; } return end[cur]; } // 查询前缀 intcountPrefix(string word){ int cur = 1; for (auto c : word) { int path = c - 'a'; if (nexts[cur][path] == 0) return0; cur = nexts[cur][path]; } return pass[cur]; } // 删除word voiderase(string word){ if (countWord(word) > 0) { int cur = 1; pass[cur]--; for (auto c : word) { int path = c - 'a'; if (--pass[nexts[cur][path]] == 0) { nexts[cur][path] = 0; return; } cur = nexts[cur][path]; } end[cur]--; } }
/* 堆排序 时间复杂度 O(n*log n) 空间复杂度 O(1) 稳定性 无 */ // 向上调整 voidheapInsert(vector<int>& heap, int i){ while (i >= 1 && heap[i] > heap[(i - 1) / 2]) { swap(heap, i, (i - 1) / 2); i = (i - 1) / 2; } }
// 向下调整 voidheapify(vector<int>& heap, int i, int size){ int l = 2 * i + 1; while (l < size) { // 从左右孩子中选出最大的孩子 int mx = l + 1 < size && heap[l] < heap[l + 1] ? l + 1 : l; // 比较最大的孩子与当前元素 if (heap[i] >= heap[mx]) break; // 如果当前元素比最大的孩子小 则向最大的孩子移动 swap(heap, i, mx); // 更新 i, l i = mx; l = 2 * i + 1; }
}
// 建堆 自下而上 voidbuild_bottom(vector<int>& ns){ int n = ns.size(); for (int i = n - 1; i >= 0; --i) { heapify(ns, i, n); } }
// 建堆 自上而下 voidbuild_top(vector<int>& ns){ int n = ns.size(); for (int i = 0; i < n; ++i) { heapInsert(ns, i); } }
voidheapSort(vector<int>& nums, void(*build)(vector<int>& ns)){ int n = nums.size(), last = n; // 建堆 build_bottom(nums); // 大数归位 while (last > 1) { swap(nums, 0, last - 1); --last; heapify(nums, 0, last); } }